在游戲運營與產品優化的過程中,日志分析是洞察玩家行為、評估系統表現、發現潛在問題的核心手段。上一部分我們探討了日志分析的價值與基礎框架,本篇將深入關鍵的技術執行層:如何實現“無死角”的數據采集,以及采集后如何進行高效、準確的數據處理。
一、 無死角數據采集:構建全面的數據感知網絡
“無死角”并非指記錄所有無用信息,而是指有策略、有重點地覆蓋所有可能影響游戲體驗、平衡性、營收和長期留存的關鍵環節。它需要一套精心設計的采集方案。
- 明確采集目標與維度:
- 用戶行為流:從賬號創建、新手引導、核心玩法循環(如對戰、副本、抽卡)、社交互動(聊天、組隊、公會)、到付費行為(點擊商城、購買道具、充值成功/失敗),每一步都需要埋點。
- 系統性能與健康狀況:客戶端幀率、加載時長、崩潰日志、服務器響應延遲、數據庫查詢耗時、網絡丟包率等。
- 經濟系統與平衡性:虛擬貨幣的產出與消耗流水、熱門物品/角色的使用率與勝率、任務完成率、關卡通過率與卡點分析。
- 業務與運營活動:活動頁面的曝光、點擊、參與及完成數據,廣告投放的轉化漏斗。
- 采集技術實現要點:
- 客戶端埋點:采用SDK(如自研或第三方數據分析平臺SDK)進行代碼埋點。趨勢是向“無埋點”或“可視化埋點”發展,以降低開發負擔,但關鍵業務事件仍需精準代碼埋點以保證數據質量。
- 服務端日志:所有服務端邏輯,特別是涉及資產變動、規則校驗的交易邏輯,必須輸出結構化日志(如JSON格式)。這是數據準確性的最終防線。
- 多端與全鏈路追蹤:對于跨平臺(PC、移動、主機)游戲,需統一用戶ID體系。引入TraceID實現單次用戶請求的全鏈路追蹤(從客戶端發起,經過多個微服務,到數據庫返回),便于排查復雜問題。
- “黑暗數據”的采集:不要只記錄成功事件。失敗的操作(如充值失敗、登錄失敗、匹配超時)、用戶的取消行為(將物品放入購物車后關閉頁面)、異常路徑(利用漏洞或非預期操作)往往包含更深層的問題信號。
二、 數據處理:從原始日志到分析就緒的數據資產
采集到的原始日志是雜亂、龐大且原始的。數據處理的目的,是將這些“數據原油”提煉成可供分析的“標準汽油”。
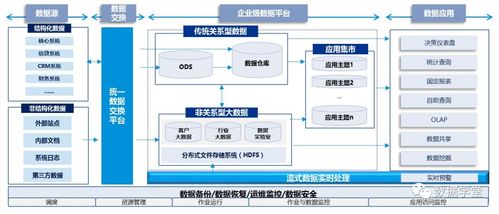
1. 數據流水線架構:
典型的流程是:采集 -> 傳輸 -> 存儲 -> 清洗與標準化 -> 建模與聚合 -> 服務于應用層。
- 傳輸:使用高吞吐、高可用的消息隊列(如Kafka、Pulsar)進行日志實時收集,解耦采集端與處理端。
- 存儲:原始日志通常存入成本較低的分布式文件系統(如HDFS)或對象存儲,用于審計和回溯。實時數據可入實時數倉(如ClickHouse),分析型數據入離線數倉(如Hive)。
- 數據清洗與標準化的核心任務:
- 格式校驗與修復:檢查日志格式是否符合規范,對缺失關鍵字段(如用戶ID、時間戳)的記錄進行標記或按規則修復/剔除。
- 數據去重:因網絡重發等原因導致的重復日志需要被識別并去重。
- 異常值處理:識別并處理明顯不合理的數據(如戰斗傷害值為負數、單次充值金額異常巨大)。
- 字段解析與豐富:從原始日志中解析出結構化字段,并關聯元數據(如將道具ID關聯道具名稱、類型)、基于業務規則打標簽(如定義“高價值用戶”、“流失風險用戶”)。
- 時間對齊:統一所有日志的時間戳為標準時區(如UTC),并處理客戶端與服務端可能存在的時間差。
3. 數據建模與聚合:
這是將數據轉化為業務語言的關鍵一步。在數據倉庫中構建維度建模。
- 事實表:記錄具體的業務事件,如“付費事實表”、“登錄事實表”、“戰斗回合事實表”。包含事件時間、用戶ID、相關維度ID和度量值(如金額、時長)。
* 維度表:描述事實的屬性,如“用戶維度表”(用戶屬性、注冊信息)、“時間維度表”、“道具維度表”、“渠道維度表”。
通過將事實表與維度表關聯,我們可以輕松地回答諸如“過去7天,來自A渠道的付費用戶,在周末最喜歡購買哪類道具?”等復雜業務問題。
4. 質量監控與治理:
數據處理不是一勞永逸的。必須建立數據質量監控體系:
- 完整性監控:每日/每小時數據量是否在正常波動范圍內?關鍵字段缺失率是否超標?
- 準確性監控:通過關鍵指標(如DAU、總收入)的交叉驗證,或與業務系統數據庫對賬,確保數據計算準確。
- 及時性監控:數據從產生到可用于分析,延遲是否在SLA(服務等級協議)內?
###
“無死角采集”為分析提供了全面而豐富的原料,“專業化處理”則將這些原料轉化為穩定、可信、易用的數據產品。這兩個環節緊密結合,構成了游戲數據驅動決策的堅實基石。只有確保了數據源頭和數據流程的質量,后續的統計分析、用戶畫像、A/B測試和智能推薦等高級應用才能真正發揮價值,指引產品迭代與運營決策駛向正確的方向。在下一部分,我們將探討如何基于處理好的數據,進行深入的洞察分析與應用實踐。